
Ideation
Detecting tuberculosis from breath? sounds impossible right? that was when I first heard it.
The story started when one of my close friends invited me to join a national scale competition in Indonesia. At that time, we actually didn’t have an idea what we wanted to make yet, sounds like a trap right haha, but it’s okay, we discussed… day by day we found out what potentially could win and we could make, and the idea kept changing.
When we want to make an idea happen, it should make sense right (?), that’s why… we read many papers, found out what others have done, what their methodology was, and so on.
Until finally, we made a decision to focus on the health sector and we chose to make a tuberculosis detector from breath. Sounds impossible at the time if you just heard about it, but this decision is actually possible, I will tell you why when I’m done with this post.
After reading from several sources, the idea is we need breath from someone and analyze the VOCs in their breath. There are similar tools made before related to disease detection from breath, called e-nose, used for detecting COPD, diabetes, and many more. From here we understood that it is also possible if applied to tuberculosis. In several journals we also found that people infected with tuberculosis have VOCs in their breath that are different from healthy people, from there we concluded that it’s possible [1, 2].
Simply put like that, now a problem arises. We already know what VOCs can be used to identify tuberculosis, but how can we analyze those VOCs? Maybe you adhere to using sensors (?), but you know, the tool to detect specific VOCs according to the research we got is very expensive…. whereas the funds we have are impossible to buy that tool, the tool is called GC/MS (Gas Chromatography–Mass Spectrometry).
This is where the power of machine learning is needed. The second idea is… roughly speaking we don’t need to know the specific VOCs, but we can utilize machine learning algorithms to read patterns from those VOCs. Those patterns are from breath data given to the machine learning algorithm to create a model that can identify tuberculosis from breath.
The concept is like our nose, when we smell durian for example, from the nose sensors we have and then the data is sent to the brain, we know it smells like durian, but we don’t know specifically about the VOCs. Therefore, we don’t need to use the GC/MS tool but just cheap gas detection sensors of the Metal Oxide Sensor type, namely MQ-2, MQ-3, MQ-4, MQ-6, MQ-7.
Prototyping
The work started from design and making the tool. This was a process that was quite long and full of trial and error, I feel it’s impossible to tell in detail, the tool can be seen as in this picture.

The prototype is done, now is the time for us to try the tool. The next step here is we need to collect data from patients infected with tuberculosis and healthy patients.
Honestly, this was a process that was quite long and more tiring than making the tool. We went from one hospital to another, puskesmas (community health center), even coming directly to houses to get breath samples, certainly with health protocols according to procedure. Errors in the prototype sometimes cannot be avoided, sometimes ran out of battery, there were problems on the server, or even there were problems in the prototype itself. But here I learned a lot of things, very worth it.
I in this team was responsible for the Software system and AI model part. What I did here was providing a place for data collection, so I created a system where the system can receive breath data from the prototype via RestFul API, and in that system also the labeling process is done which can be accessed via website.
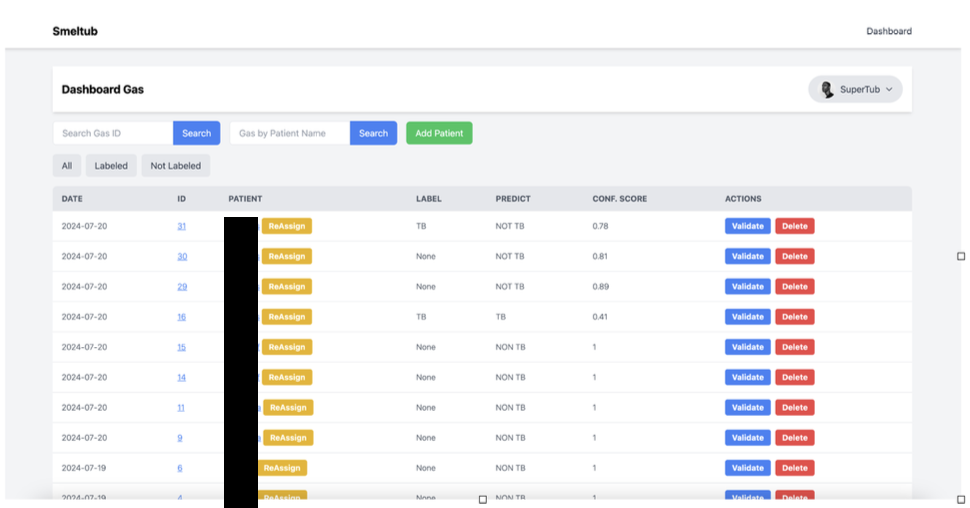
Machine Learning Model
Data has been collected and deemed sufficient, now is the time to make the machine learning model.
This stage is no less tiring than the previous stage. Here I worked alone, not as a team. I had to read various articles to find out the optimal way so that the model accuracy is good from the data that has been collected previously.
So, each breath sample was collected for 2 minutes. There, each sensor will have its own value. The data will go through a preprocessing stage before being entered into the model, including removing outliers and filtering.
After the data is cleaned, the next stage is feature selection. Based on reading articles too, here the features extracted from that data are Pearson correlation coefficients and simple descriptive statistics.
- Max
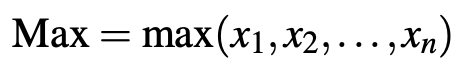
- Min
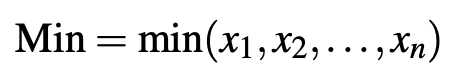
- Range
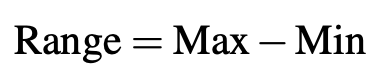
- Pearson Correlation Coefficient
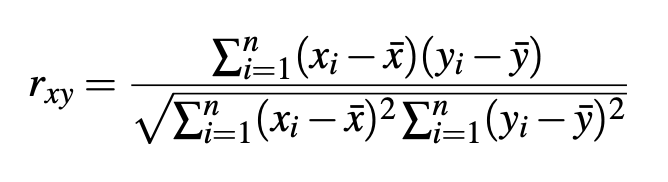
When using these features to represent information from the breath data sample as a whole (120 seconds), the resulting model accuracy was not optimal, the model could not distinguish well between TB patients and healthy individuals.
I tried reading again some literature [3, 4], and found one using sampling techniques. Simply put, we don’t take all the data, but take the most optimal data, and the result accuracy increased. From 2 minutes of data, only 30/40 seconds at the beginning were used / the best.
This means, if this tool is ready to be used later, breath samples collected don’t have to wait for 2 minutes again, but just 1/4 of it.
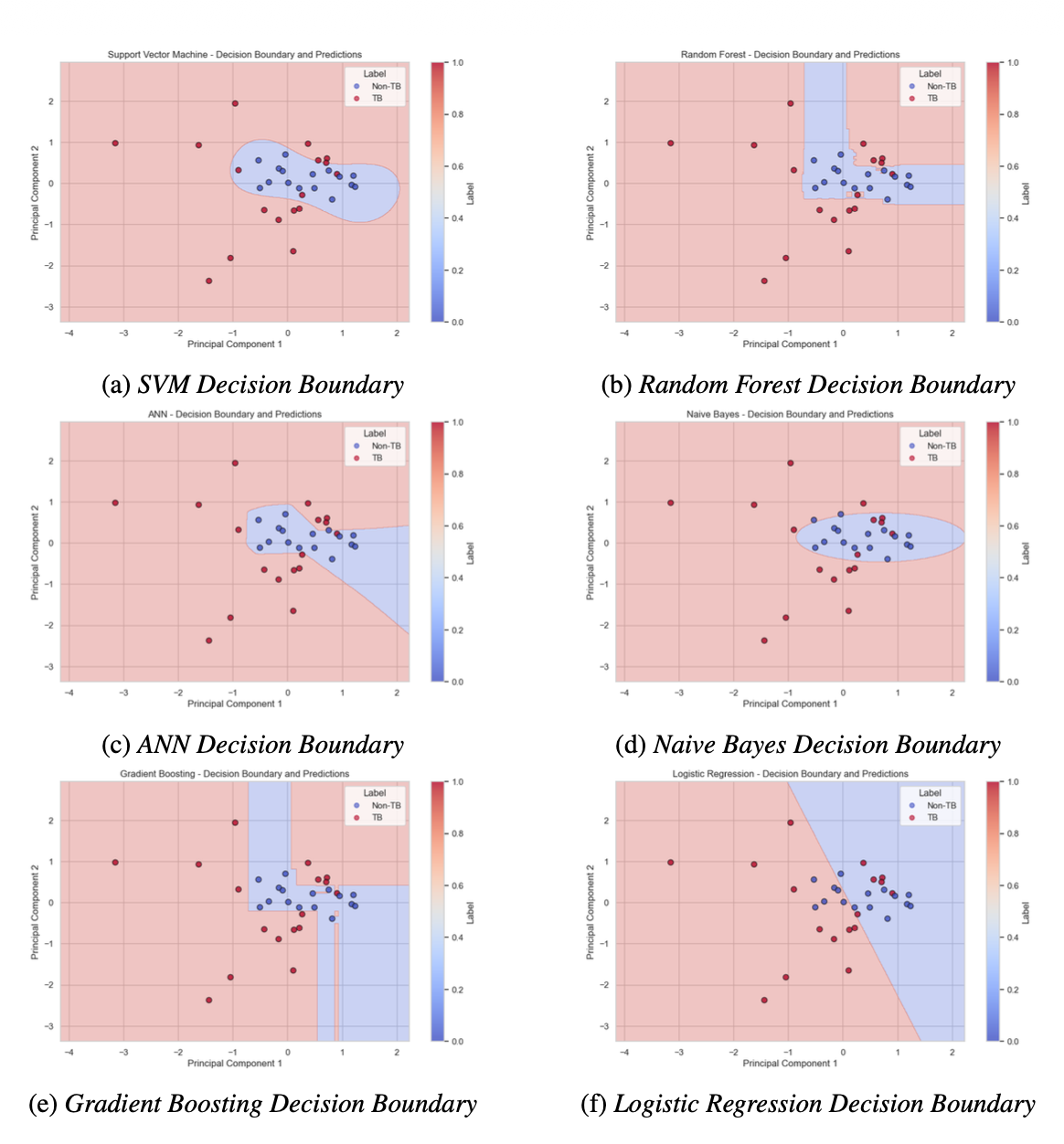
These features have large data dimensions. Just imagine one breath data inside has signal data from 5 gas sensors. Before being given to the model, the data will be processed first with the Principal Component Analysis (PCA) method. This method will reduce the data dimensions to 2 dimensions and is also easy to visualize.
The result is like this:
And the resulting model accuracy is:
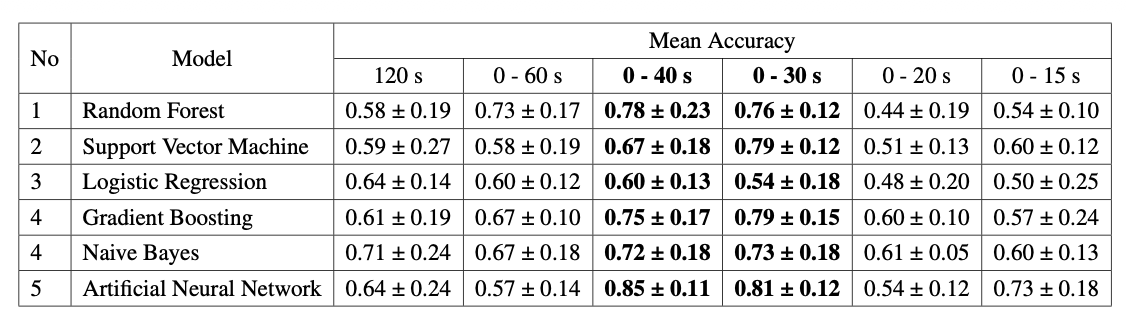
You can judge for yourself which algorithm is suitable for this case.
Conclusion
Before closing this writing, I also want to be honest and add something. If colleagues read this writing and want to do similar innovation, there are several things that need to be paid attention to. This result needs further testing for sure. What was tested in this project focused too much on the model accuracy side only. Many other things need to be paid attention to, such as tool consistency, sensors, data collection procedures, amount of data collected, and much more. Because of limited funds and time, unfortunately, we didn’t do that optimally, but this also gives us an illustration that a project like this is very possible to do and beneficial for many people in the future.
Achievement
Projects like this, rather than doing nothing, we also entered into competitions. Alhamdulillah we got several awards.


